How it works:
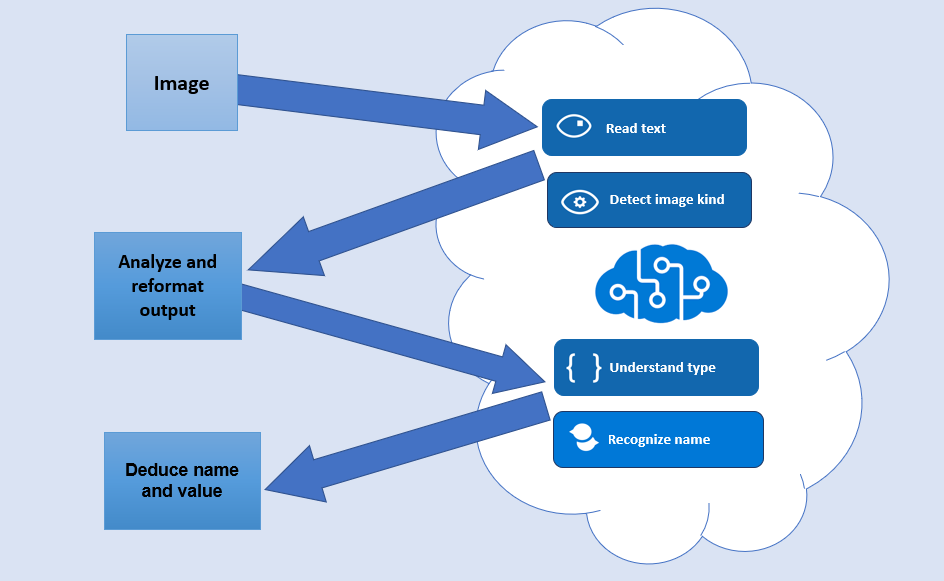
The uploaded image is first processed by custom vision and computer vision. The custom vision is trained to detect different text formats. The computer vision fetches all printed text from the image. The web application then combines the information from both these APIs and reformats it into the required text. The resulted text is then sent to LUIS and a QnA maker. LUIS detects for patterns. This helps identify which part of the text is a field name and which part is sample data. The QnA maker takes the field names and detects field types based on it. The information from both these APIs are put together to conclude what is the field name and its type.